
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- HTML
- tibero
- putty
- Python DataFrame
- 파이썬 데이터프레임
- 리눅스 명령어
- it 용어
- RFP
- 리눅스
- csharp
- VirtualBox
- 알고리즘
- 파이썬 알고리즘
- 코딩테스트
- 데이터베이스
- 오라클
- Oracle
- MariaDB
- Python 라이브러리
- PYTHON
- sql
- linux
- dbeaver
- Algorithm
- it용어
- 파이썬 전처리
- python algorithm
- Oracle VM VirtualBox
- 파이썬
- C#
- Today
- Total
오경석의 개발노트
Python_loc, iloc 본문
loc, iloc 차이
- loc(location)는 데이터프레임의 행이나 컬럼에 label이나 boolean array로 접근
- iloc(integer location)는 데이터프레임의 행이나 컬럼에 인덱스 값으로 접근
data = {
"2015": [9904312, 3448737, 2890451, 2466052],
"2010": [9631482, 3393191, 2632035, 2431774],
"2005": [9762546, 3512547, 2517680, 2456016],
"2000": [9853972, 3655437, 2466338, 2473990],
"지역": ["수도권", "경상권", "수도권", "경상권"],
"2010-2015 증가율": [0.0283, 0.0163, 0.0982, 0.0141]
}
columns = ['지역', '2015', '2010', '2005', '2000', '2010-2015 증가율']
index = ['서울', '부산', '인천', '대구']
df = pd.DataFrame(data, index=index, columns=columns)
df
iloc를 이용해서 데이터에 접근하기
df.iloc[0] # 첫번째 행 접근
>>> # Series 반환
지역 수도권
2015 9904312
2010 9631482
2005 9762546
2000 9853972
2010-2015 증가율 0.0283
Name: 서울, dtype: objectdf.iloc[[0]] # 이중대괄호[[]]는 DataFrame을 반환
df.iloc[-1] # 마지막 행 접근
>>> # Series 반환
지역 경상권
2015 2466052
2010 2431774
2005 2456016
2000 2473990
2010-2015 증가율 0.0141
Name: 대구, dtype: objectdf.iloc[[-1]]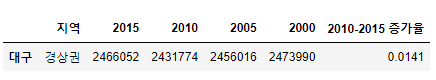
df.iloc[:,0] # 첫번째 열 접근
>>> # Series 반환
서울 수도권
부산 경상권
인천 수도권
대구 경상권
Name: 지역, dtype: objectdf.iloc[:,-1] # 마지막 열 접근
>>> # Series 반환
서울 0.0283
부산 0.0163
인천 0.0982
대구 0.0141
Name: 2010-2015 증가율, dtype: float64df.iloc[[0, 3], [1, 3]] # 특정 행과 열을 DataFrame으로 반환
loc를 이용해서 데이터에 접근하기
df.loc['서울'] # 첫번째 행 접근
>>> # Series 반환
지역 수도권
2015 9904312
2010 9631482
2005 9762546
2000 9853972
2010-2015 증가율 0.0283
Name: 서울, dtype: objectdf.loc['서울':'부산']
df.loc[:, '2010'] # 레이블 이름이 '2010'인 열에 접근
>>> # Series 반환
서울 9631482
부산 3393191
인천 2632035
대구 2431774
Name: 2010, dtype: int64조건부 반환
df.loc[df['2015'] > 300e4]
특정 컬럼이 포함된 조건부 반환
df.loc[df['2015'] > 300e4, ['2015']]
짝수 행만 추출(loc, iloc 공통)
df.iloc[::2, :]
출처 : https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.loc.html
pandas.DataFrame.loc — pandas 1.4.4 documentation
A slice object with labels, e.g. 'a':'f'. Warning Note that contrary to usual python slices, both the start and the stop are included
pandas.pydata.org
출처 : https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html
pandas.DataFrame.iloc — pandas 1.4.4 documentation
A callable function with one argument (the calling Series or DataFrame) and that returns valid output for indexing (one of the above). This is useful in method chains, when you don’t have a reference to the calling object, but would like to base your sel
pandas.pydata.org
출처 : https://gagadi.tistory.com/16
[Python] Pandas : loc 과 iloc 의 차이
Python Pandas 파이썬 판다스 loc과 iloc의 차이 ✔ loc 1. 데이터프레임의 행이나 컬럼에 label이나 boolean array로 접근. 2. location의 약어로, 인간이 읽을 수 있는 label 값으로 데이터에 접근하는 것이다...
gagadi.tistory.com
출처 : https://bigdaheta.tistory.com/42
[pandas] 2-2. loc와 iloc 차이와 사용방법
🖇 이전 글 [pandas] 2-1. loc와 iloc 차이와 사용방법 파이썬 기초 문법을 공부할 때 인덱싱(indexing) 개념에 대해 배웠을 것이다. '인덱싱'에 대해 잘 모른다면 (클릭). 인덱싱은 데이터 프레임에도 적
bigdaheta.tistory.com
'프로그래밍 언어 > Python' 카테고리의 다른 글
| Python_DataFrame Column 이름 변경, 삭제 (0) | 2022.09.08 |
|---|---|
| Python_Numpy (0) | 2022.09.06 |
| Python_DataFrame (1) | 2022.09.06 |
| Python_Series (0) | 2022.09.06 |
| Python_Pandas (0) | 2022.09.05 |



